

This past week was my last in Europe until the end of May. I started in London, wrapping up my last full day at Queen Mary University of London on Monday and then heading to CERN to work with my colleagues in the SMU ATLAS group, including a student and a post-doc. My time at CERN was an intense whirlwind of activity, this time focused not on code development but on automated analysis and software validation – a crucial, but missing piece, of our current distributed analysis effort. Now I am back in Dallas, having returned on Friday and begun the recovery from jet lag. This is my last day of rest at home before I hit the road with Jodi to go to Washington D.C., where she has an event related to the SuperCDMS-SNOLAB experiment and she and I together will go to Capitol Hill to meet with some of our elected Congressional representatives. But the revelation of this past week was a deep exposure to the idea that all the factory-like steps that we, as physicists, engage in to move an analysis along (over and over again) can be, in the modern computational world, delegated to automation. This will free physicists to be more creative and thoughtful, and less slave to the repetitive process of running script after script after script just to make a small update to a big data analysis.
Automating ALL THE THINGS
Validation is a dry subject. It’s a repetitive process. Every time someone makes a small change to your analysis, it is wise to rerun it and see what has changed. It’s important to be clear-headed enough during this process to think carefully about what you see. Most physicists are so worn out by having to remember to run all the little steps, or just their little step (over and over again), that it’s easy to go numb to problems in an analysis chain. It’s too simple to go blind with complacency, convinced that this time the small change someone made will have as infinitesimal an impact as the last change. But what if there is a bug? What if a mistake has been made, even in well-intentioned code changes? Vigilance is required in all physics analysis, to find mistakes before the analysis ever sees the light of day in the wider collaboration or the journal where you intend to publish it.
I am reminded of the “Freakonomics” podcast episode entitled “In Praise of Maintenance.” Maintaining things like infrastructure or code doesn’t feel like the big, sexy job people crave. It feels boring. Nobody scrambles to maintain. Nobody rushes to validate. But this is a mistake. It’s harder to repair a broken system than to maintain a functioning one. It’s also possible that while learning to maintain, you will spot the most important places where improvement can be targeted. Maintenance solves two problems. The latter of those solutions can lead to innovation. This is an underappreciated fact. Rather than innovation by random trial, you can have instead innovation by thoughtful observation. I prefer the latter.
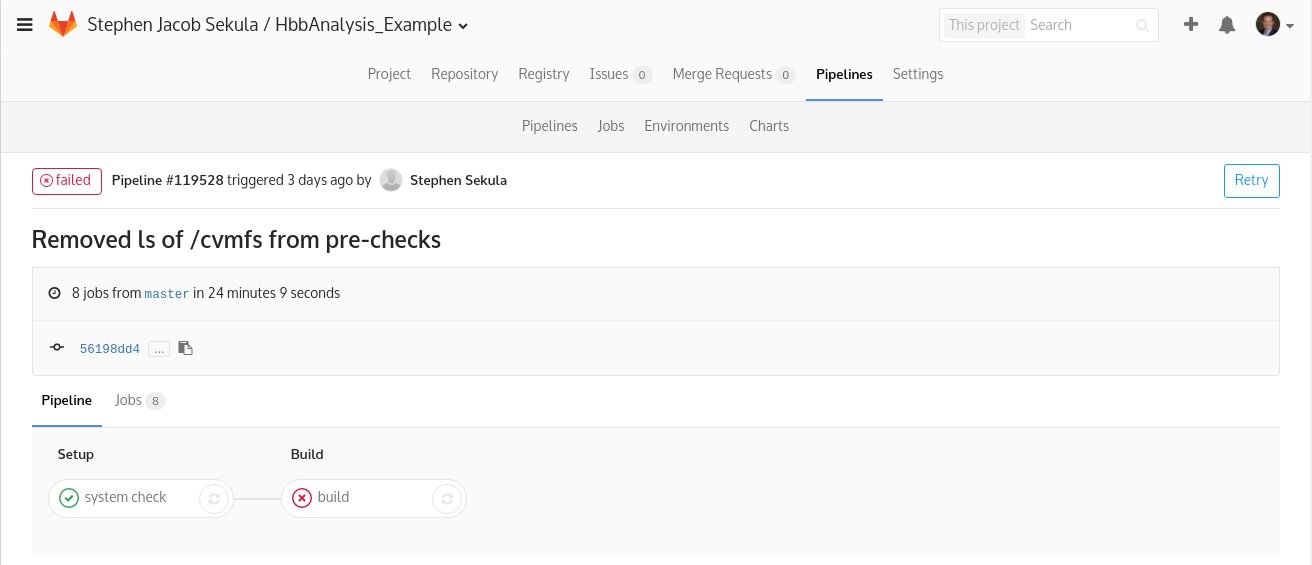
My student, M, developed a demonstration validation pipeline – a series of stages that each have to be passed to proceed to the next. This has been automated through Gitlab, the software development framework now in adoption by the ATLAS Collaboration. Gitlab allows you to define a simple YAML-based steering file where each stage of, for instance, a validation process can be encoded and executed. Output from previous stages can be saved, as “artifacts,” to pass to later stages. This is precisely the kind of automation we need, and we can customize the triggers that initiate the pipeline.
But why be limited to validation? This is what got my brain running this week, especially after meeting a PhD student at NYU who has been working with M on setting up the framework of accounts and software needed for this validation pipeline work at CERN. The NYU student is developing an approach, called RECAST, that was laid out in 2010 by his thesis adviser.

RECAST is a concept by which an analysis is archived in, for a concrete instance, a Gitlab repository. This includes not just the workhorse code, but all the steering scripts for every stage of the analysis and even input files to the initial stage of that analysis. In principle, all the CPU-intensive work is complete for 99% of the analysis – the background predictions and data are all in a small, pre-processed format (that is often the most resource-intensive stage, requiring days of running on the global computing GRID). You can even store the software environment needed to reproduce that analysis in a Docker Container, one that can be loaded on-demand to execute the analysis all over again without the need to maintain a system somewhere that can be capable of running the analysis a year, or two years, or 10 years later.
You can see where this is going. Let’s say some theorist, a few years after an analysis is completed, has a neat idea for a new model that can be tested with that analysis. Nobody is left on the experiment who worked on that analysis, or maybe they are too busy doing other things. The RECAST idea lets you simply fire up a pipeline that can run the analysis, summon a Docker Container to execute the stages, and inject the new model into the process when interpreting the data. It’s elegant.
I am intrigued by this approach. I imagine doing this with an existing analysis, writing a pipeline that captures all the stages of the analysis after the most resource-intensive first part. Re-running the analysis in a pinch then becomes an exercise in automated cloud computing. Load up the changes to the Git repository, fire up the pipeline, and set it running. Go get a coffee. Grab a nice lunch. Read a paper from your favorite journal. Rest the mind. When you come back, the results are ready for you to THINK about. No longer are you tired out from having to come back, run the next step, remember how to configure your environment to do it, finding a free machine to run it on, etc. All the factory work is done. You are free to be the intellectual that you trained to be. Understanding nature benefits from an unburdened mind, and this approach promises to allow more burdens to be relieved.
I have only just begun to appreciate how modern cloud-based technology can allow physicists to think forward more carefully about big data analysis. I know that others already get this concept, but I think not enough physicists get it enough to deeply appreciate what it means for us as thinkers and as creative individuals. It’s fun to write a script to automate your analysis. It’s tedious to run it over and over again. This allows you to write that process once and have it executed on-demand, freeing you to think more deeply about what you are trying to accomplish, how you are going to do it, and how you could improve each step in the process.

My time at CERN was exhilarating. As I am now recovering a bit from jet lag, I am trying to think ahead 4 steps in to the fall, when we’ll want to have a smoothly running analysis with lots of validation. But what about adding real-time automation of the analysis? That’s an exciting prospect. Why just validate, when you can also execute the analysis as well?
Also: Docker Swarm. I just like saying that.
Returning Home
 I was very eager to return home on Friday. I enjoyed my time in London and at CERN, but I was ready to go home. I missed Jodi terribly. I was up at 04:30 on Friday, grabbed a cab to the airport at 05:00, and was off to London to connect to Dallas at 07:20. The security lines at the Geneva airport were a nightmare, but I had built plenty of time into my trip. I was misdirected to the wrong terminal by American Airlines security personnel at Heathrow. They looked my ticket, asked me a bunch of security questions, but NEVER bothered to actually read the ticket to see that I was on a British Airways flight out of Terminal 5, not on one of the American Airlines flights to Dallas out of Terminal 2. They see, but they do not observe. Worrying in a security staff.
I was very eager to return home on Friday. I enjoyed my time in London and at CERN, but I was ready to go home. I missed Jodi terribly. I was up at 04:30 on Friday, grabbed a cab to the airport at 05:00, and was off to London to connect to Dallas at 07:20. The security lines at the Geneva airport were a nightmare, but I had built plenty of time into my trip. I was misdirected to the wrong terminal by American Airlines security personnel at Heathrow. They looked my ticket, asked me a bunch of security questions, but NEVER bothered to actually read the ticket to see that I was on a British Airways flight out of Terminal 5, not on one of the American Airlines flights to Dallas out of Terminal 2. They see, but they do not observe. Worrying in a security staff.
But I had plenty of time to make up from their mistake. I got to Terminal 2, was turned back by another security official, and returned to Terminal 5. Ping. Pong.
I relaxed at a restaurant in Terminal 5 until it was time to board my flight, and then settled in for the 10-hour ride home. I get antsy on planes, especially when I want to just be home, so I distracted myself with “Rogue One” and its associated “Making of…” documentary (this cemented Riz Ahmed as my absolute favorite actor and my absolute favorite character – Bodhi Rook – from this movie), as well as season 3 of “Sherlock,” which I haven’t watched since it first aired. I also did some editing for the book I am co-authoring, and watched some lectures on Machine Learning from a colleague of mine at CERN. It was a productive – if damned long – flight. I’ll say this, though: British Airways has better vegan food than American Airlines [1].

The weather here was hot on Friday but crashed on Saturday, with the high today being only in the 60s F. This meant a cold front swept through yesterday, and this led to at least 2 tornadoes touching down east of here. We could see how foreboding the sky turned in the late afternoon, an ominous sign of the horror to come for Canton, Texas.
The week ahead
 Tomorrow, Jodi and I leave for Washington D.C. She has an event at the Canadian Embassy, an event focused on the next phase of the SuperCDMS experiment: SuperCDMS-SNOLAB, sited at the SNOLAB facility in Sudbury, Canada. We’ll be visiting congressional offices on Wednesday, and then we’ll be back on Thursday morning. I’ll be attending a dinner at SMU on Thursday night, and then maybe life can return to something resembling sanity and routine on Friday. Maybe.
Tomorrow, Jodi and I leave for Washington D.C. She has an event at the Canadian Embassy, an event focused on the next phase of the SuperCDMS experiment: SuperCDMS-SNOLAB, sited at the SNOLAB facility in Sudbury, Canada. We’ll be visiting congressional offices on Wednesday, and then we’ll be back on Thursday morning. I’ll be attending a dinner at SMU on Thursday night, and then maybe life can return to something resembling sanity and routine on Friday. Maybe.
[1] I’m not vegan, but here’s a travel tip: if you put in your flight profile that you are vegan, you not only get served food first (they bring yours out as a special meal), you get better-quality food.




{kind=link}