
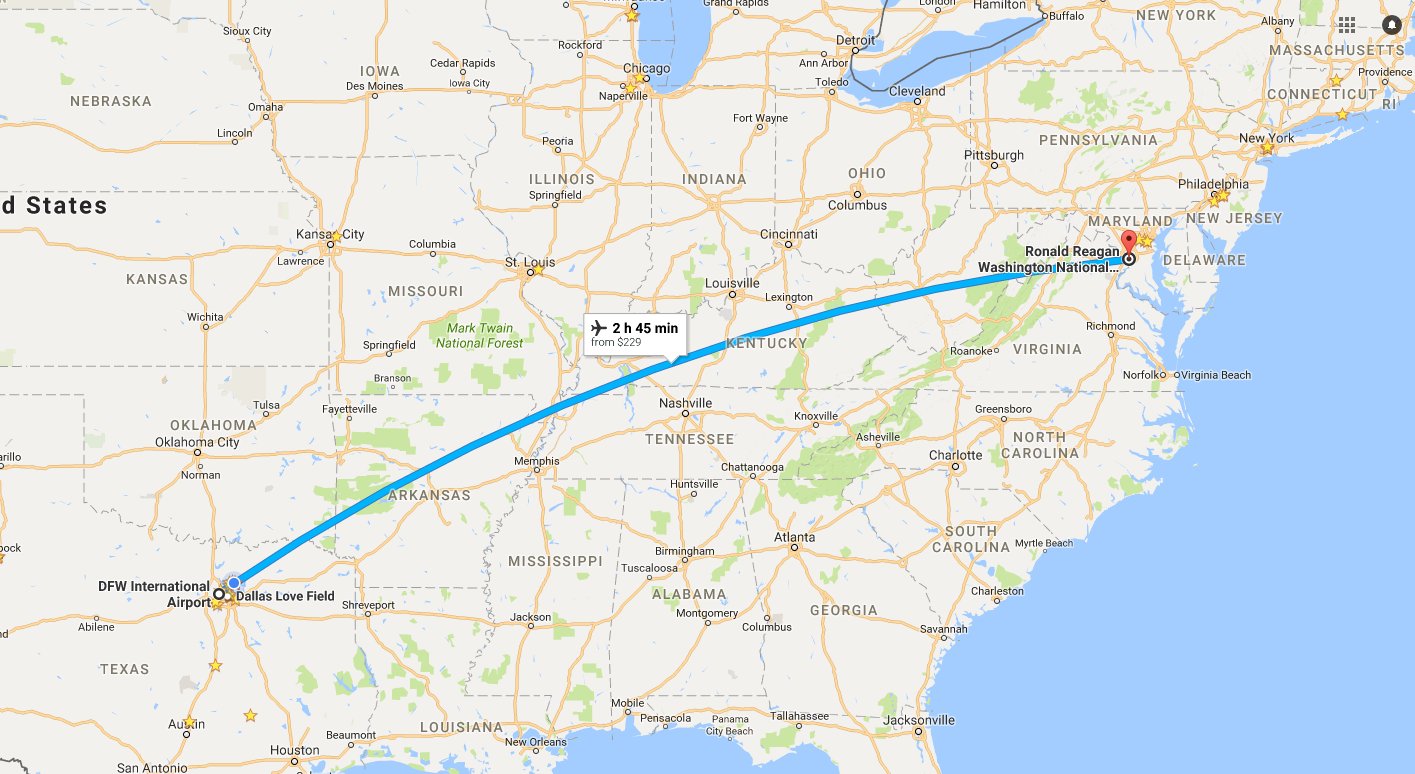
This past week was my last in Europe until the end of May. I started in London, wrapping up my last full day at Queen Mary University of London on Monday and then heading to CERN to work with my colleagues in the SMU ATLAS group, including a student and […]
Monthly Archives: April 2017
7 posts

Given how much the past few months have been largely about “eating the seed” corn by threatening to pillage the nation’s scientific capabilities, this week was comparably more uplifted. Having reached a tipping point with the rhetoric of the current president, scientists and science advocacy organizations started planning a “March […]
This was quite a week. It began with the long Easter weekend here in the UK, which came to an exceptional end for me on Monday at St. Martin-in-the-Fields for a performance of Handel’s “Messiah” and a night out with (and I love to say these words) my publisher and […]

This last week has been eventful! It began with an early morning return to Dallas from Connecticut, fighting the beginning of an annoying cold. After a couple of days at home, I was on a plane again, this time to London to spend 13 days working with colleagues at […]

Signs and portents abound in rhetoric from the current executive branch of the United States. Science, the only known way of establishing reliable information about the natural world, should be essential as a part of policy decision making. I try to highlight places where science and science-related agencies in the […]
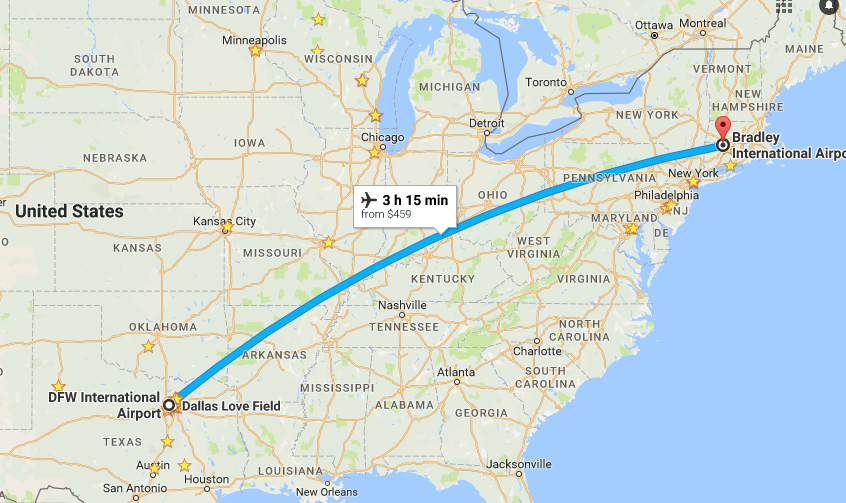
The last couple of weeks have been quite a mix, with the first one being not-so-interesting (just another week at work in Dallas) and the second one being overly exciting (travel to Connecticut, visits to my old public high school, and a concert in Boston. I don’t handle lack of […]
The US President still has selected no science adviser, leaving scientific information assessment and scientific findings absent from policy making in the White House. The blindness and deafness to scientists and scientific assessment has re-emboldened science denialism in the U.S., evidenced by recent events. Scientific information relating to climate, energy, […]